Databricks has evolved into a platform with two compute “planes” that can execute workloads:
- Classic compute plane (customer-managed networking + compute in your cloud account/VPC), which runs in an AWS account (or whatever your CSP is), within the customer’s AWS organization.
- Serverless compute plane (Databricks-managed compute that you consume on-demand), which is managed and runs within DataBricks’ AWS organization.
In a lot of organizations, the reality becomes a hybrid model: you run and govern both classic and serverless workloads at the same time. That hybrid is not automatically a problem, but it does introduce two sets of operational and security decisions that you must manage intentionally.
This post explains the architecture, why hybrid happens, when you need it, and when you should avoid it.
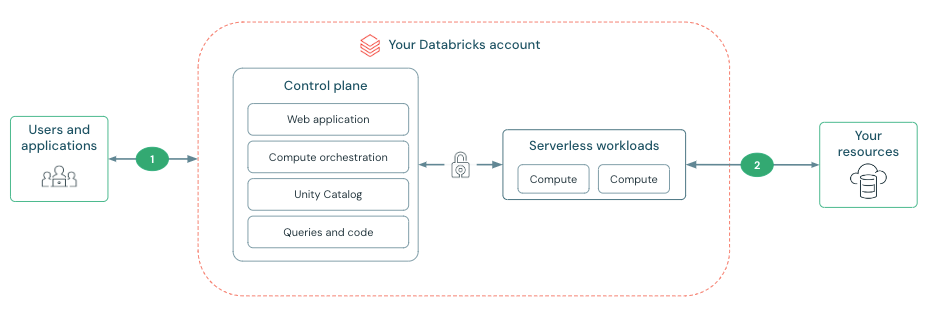
The architecture: control plane vs compute planes
Databricks is commonly described as:
- Control plane: workspace services, orchestration, web app, APIs, running in DataBricks account
- Compute plane(s): where code actually runs, within the customer’s account
Two important Databricks networking facts (that simplify a lot of “is this exposed to the internet?” fear):
- Connectivity between the control plane and compute planes is over the cloud provider backbone, not the public internet.
- Both classic and serverless compute are designed to run without public IPs on compute nodes.
Where things diverge is who owns the network boundary and the runtime.
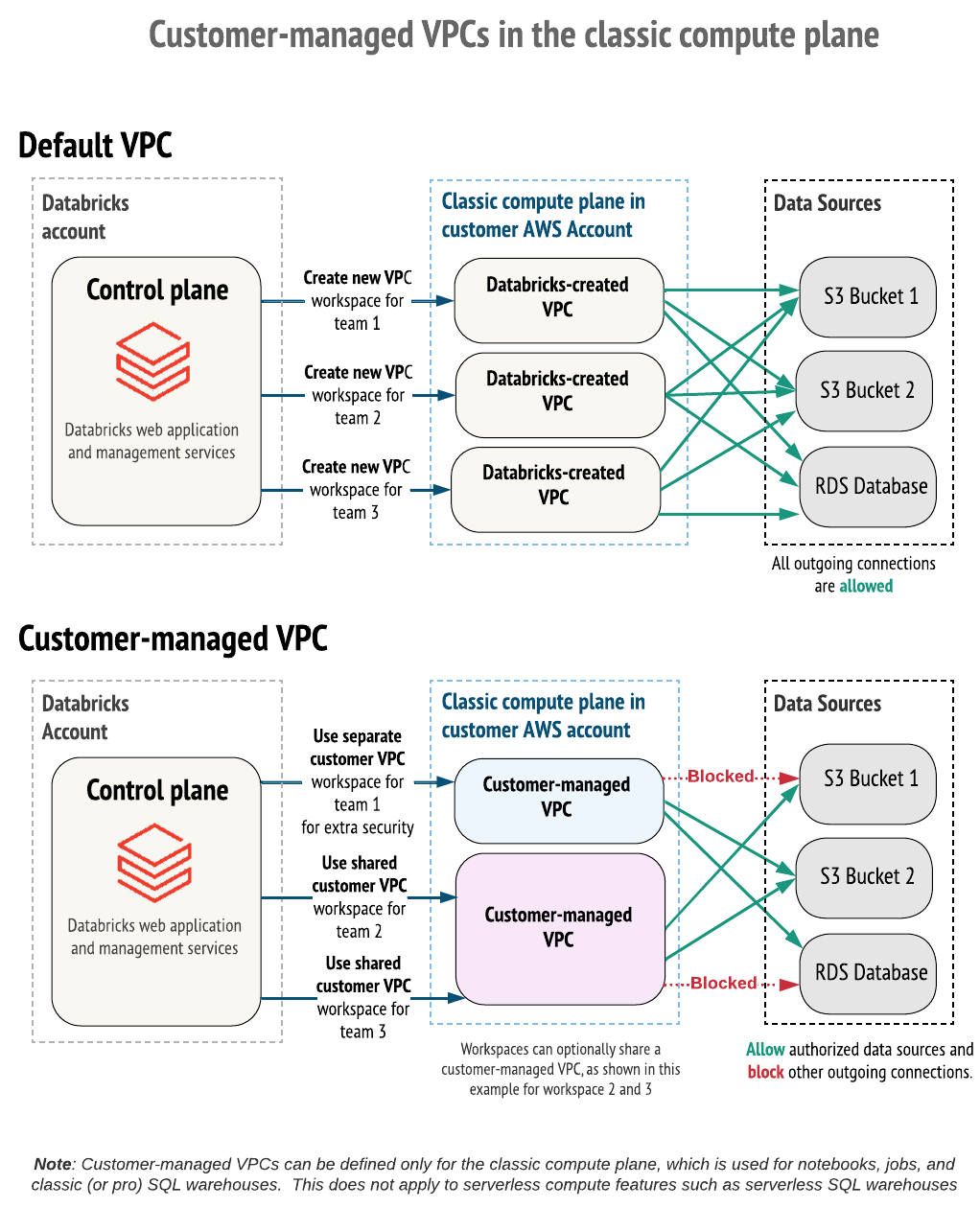
Classic compute plane (what you get, what you own)
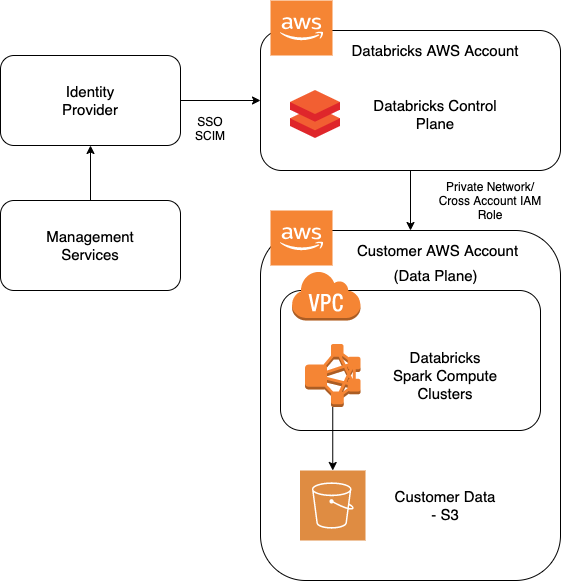
Classic compute is the model many teams started with:
- Compute runs in a VPC (Databricks-managed or customer-managed).
- Secure cluster connectivity (default) uses a relay/tunnel so clusters can connect outbound to the control plane using HTTPS (port 443) without open inbound ports.
- You can use additional networking features like VPC peering and AWS PrivateLink to further lock down paths.
Operationally, classic compute gives you maximum control, but you pay for it:
- you own more of the network design (subnets, routes, endpoints, firewalls)
- you own more of the “what can this cluster talk to?” story
- you own more of the lifecycle “snowflake cluster” risk if you don’t enforce IaC
Serverless compute plane (what you get, what you give up)
Serverless compute flips the model:
- Databricks allocates and manages compute on-demand.
- Start-up and scaling are faster and you reduce idle time.
- Serverless is “versionless” in the sense that it is upgraded automatically on Databricks’ rollout cadence.
The price you pay is that you can’t treat it like “a cluster I own.” You configure it through Databricks-native controls (and you accept the platform constraints).
Networking is also different. Serverless connectivity to your resources is managed through account-level constructs (for example, Network Connectivity Configurations (NCCs) on AWS), which provide:
- stable egress IPs you can allowlist on your resource firewalls
- a centralized place to manage connectivity patterns at scale
And Databricks is explicit that:
- there can be networking/data transfer costs when serverless workloads connect to customer resources
- you should align region placement to avoid cross-region charges
What “hybrid” actually means in practice
Hybrid usually looks like this:
- Serverless for:
- BI-style and analysis workloads (SQL warehouses, dashboards)
- short-lived interactive notebooks
- Databricks Apps and other “thin UI” experiences
- quick experimentation where startup latency matters
- Classic for:
- workloads that need deep control of runtime/networking
- legacy patterns and older codebases
- certain ML/engineering workloads that need capabilities not covered by serverless limitations in your environment
- tight integration to private networks/on-prem systems where your organization already has classic connectivity patterns built
The hybrid model isn’t just “two compute options.” It’s two operational control surfaces:
- Two ways to control outbound access
- Two ways to think about identity-to-data enforcement (user identity vs service principals + UC)
- Two cost models (DBUs + potentially different networking cost visibility)
- Two troubleshooting playbooks (“why is my cluster failing?” vs “why is my serverless workload failing?”)
When a company needs the hybrid model
Here are the situations where hybrid is not only common, it’s rational:
1) You have legacy workloads that can’t move quickly
If you already have:
- existing classic job clusters
- legacy libraries and dependencies
- “this works, don’t touch it” ETL pipelines
…you don’t rip that out just because serverless exists. Hybrid is your bridge.
2) You need private networking patterns that are already standardized on classic
Many enterprises have already built:
- VPC layouts
- private endpoints
- peering patterns
- firewall rules and change-management processes
If “compute must live in our VPC” is a hard requirement for some workloads, classic isn’t optional.
3) You need capabilities that are not a clean fit for serverless (today)
Serverless is powerful, but it is still a product with boundaries (and those boundaries vary by cloud, region, and feature).
If some workloads depend on:
- non-standard connectivity
- specialized dependencies
- specific runtime expectations that require classic compute behavior
…hybrid becomes the pragmatic choice: serverless where it shines, classic where you need control.
4) Your organization wants a “two-lane platform”
Hybrid can be an intentional product strategy:
- Lane A (serverless): governed self-service for analysts and light engineering
- Lane B (classic): controlled engineering lane for platform teams and heavy jobs
This can reduce friction if you explicitly define what belongs in each lane.
When a company does not need the hybrid model
Hybrid introduces complexity. If you don’t have a strong reason for both planes, you’re usually better off standardizing.
1) Greenfield orgs can often go “mostly serverless”
If you’re starting fresh and your workloads match serverless capabilities:
- you avoid a lot of VPC/networking work
- you reduce cluster lifecycle management
- you speed up time-to-first-value
In that scenario, classic compute can be the exception, not the baseline.
2) If you have strict “all compute must be customer-managed” policy
Some orgs have a hard requirement that everything runs inside a customer-owned network boundary with specific controls. If that’s you, hybrid is a distraction. Run classic, invest in IaC, make it boring.
3) If your team can’t operationalize two models
If you don’t have:
- clear ownership boundaries
- a strong identity + UC governance story
- cost attribution practices
- a security team that understands both planes
…hybrid becomes “two ways to be confused.”
Best practices for operating the hybrid model
If you do go hybrid, here’s what makes it survivable.
1) Make “lane selection” explicit
Write down rules like:
- “All dashboards and Apps are serverless.”
- “All jobs that access on-prem systems are classic.”
- “All production pipelines must use UC and approved external locations.”
If you don’t define this, teams will choose based on convenience, not architecture.
2) Centralize identity and governance (Unity Catalog as the spine)
Hybrid only works cleanly when:
- Unity Catalog is the consistent enforcement layer
- you assign access via groups (SCIM-provisioned groups if possible)
- you avoid credential sprawl (no random PATs in repos)
3) Treat networking as a first-class product
- Classic: standardize VPC patterns (subnets, endpoints, PrivateLink/peering)
- Serverless: standardize NCC usage, firewall allowlists, and egress controls
- Align regions to minimize cross-region and serverless connectivity costs
4) Make cost attribution non-optional
If you don’t measure it, serverless adoption debates turn into opinions.
- Tag workloads and workspaces.
- Use billing/usage tables to attribute DBU usage by workload type.
- Review connectivity/networking costs for serverless-to-resource paths.
5) Build two troubleshooting playbooks
Hybrid means your incident response must include both:
- classic: cluster-level failures, node capacity, init scripts, networking, dependency installs
- serverless: resource bindings, entitlements/permissions, egress policy, platform health signals, dependency limitations
If your on-call runbooks only cover classic, you will lose time when serverless is the path.
A simple decision rubric
If you’re unsure whether hybrid is necessary, ask:
- Do we have classic workloads we can’t migrate in 3–6 months?
- Do any workloads require customer-managed VPC placement or specialized networking?
- Do we have a governance layer (UC + identity) that makes both models safe?
- Can we support two operational models without confusion?
If the answer is “yes” to (1) or (2), hybrid is likely unavoidable. If the answer is “no” to (3) or (4), you should delay hybrid expansion until you fix governance and ops.
Final thought
The hybrid model is not a failure. It’s often a sign of maturity: you’re matching the compute model to the workload instead of forcing everything into one shape.
But hybrid also has a cost: two planes means two sets of controls, and your platform team needs to be deliberate about how work is routed, secured, monitored, and paid for.
Thank you for reading.
Cheers!
Jason